chapter: 10 無相関検定
【例題】サンプルデータ※データは架空 小学6年生において,1ヶ月の読書量と語彙数に関係性があるかを調べるため,1ヶ月あたりどのくらいの読書時間(時間),語彙数テストを行った。語彙数テストでは,1分間「た」の単語を出来るだけ多く生成することが求められた。読書量と語彙数に関係があるかを調べなさい。
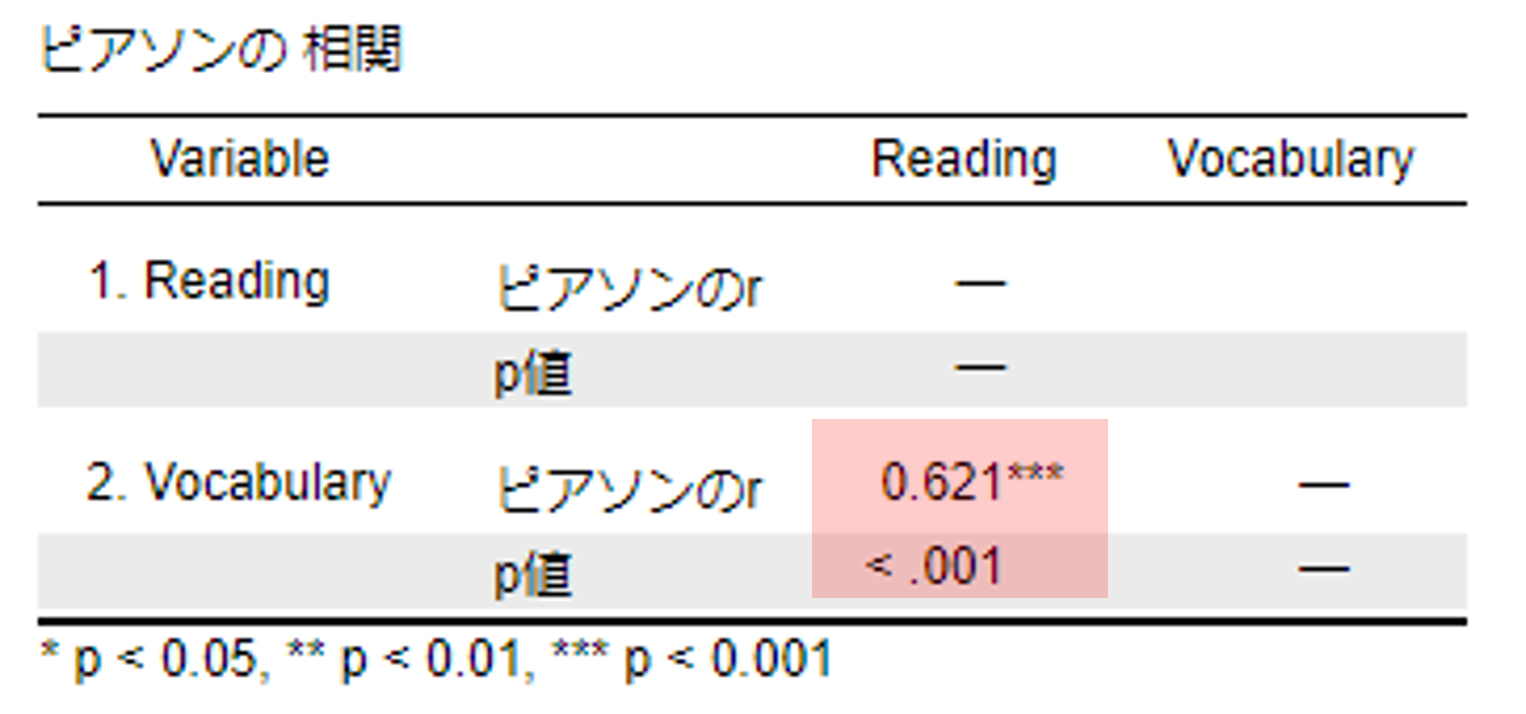
読書量は量的変数,語彙数も量的変数となる。このように量的変数同士の関連性を調べるときには,無相関検定を用いる。
データの説明
| 変数名 | 内容 | 尺度水準 |
|---|---|---|
| ID | ID | 名義尺度 |
| Reading | 1ヶ月あたりの読書時間(時間) | 比率尺度(スケール) |
| Vocabulary | 1分あたりの語彙数(個) | 比率尺度(スケール) |
10.1 分析の実施
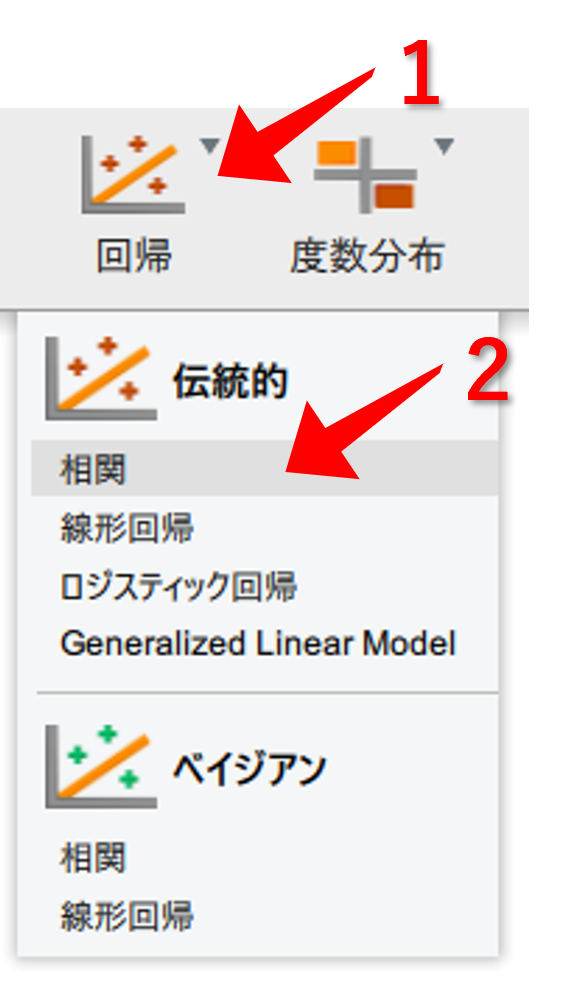
回帰- 伝統的の
相関
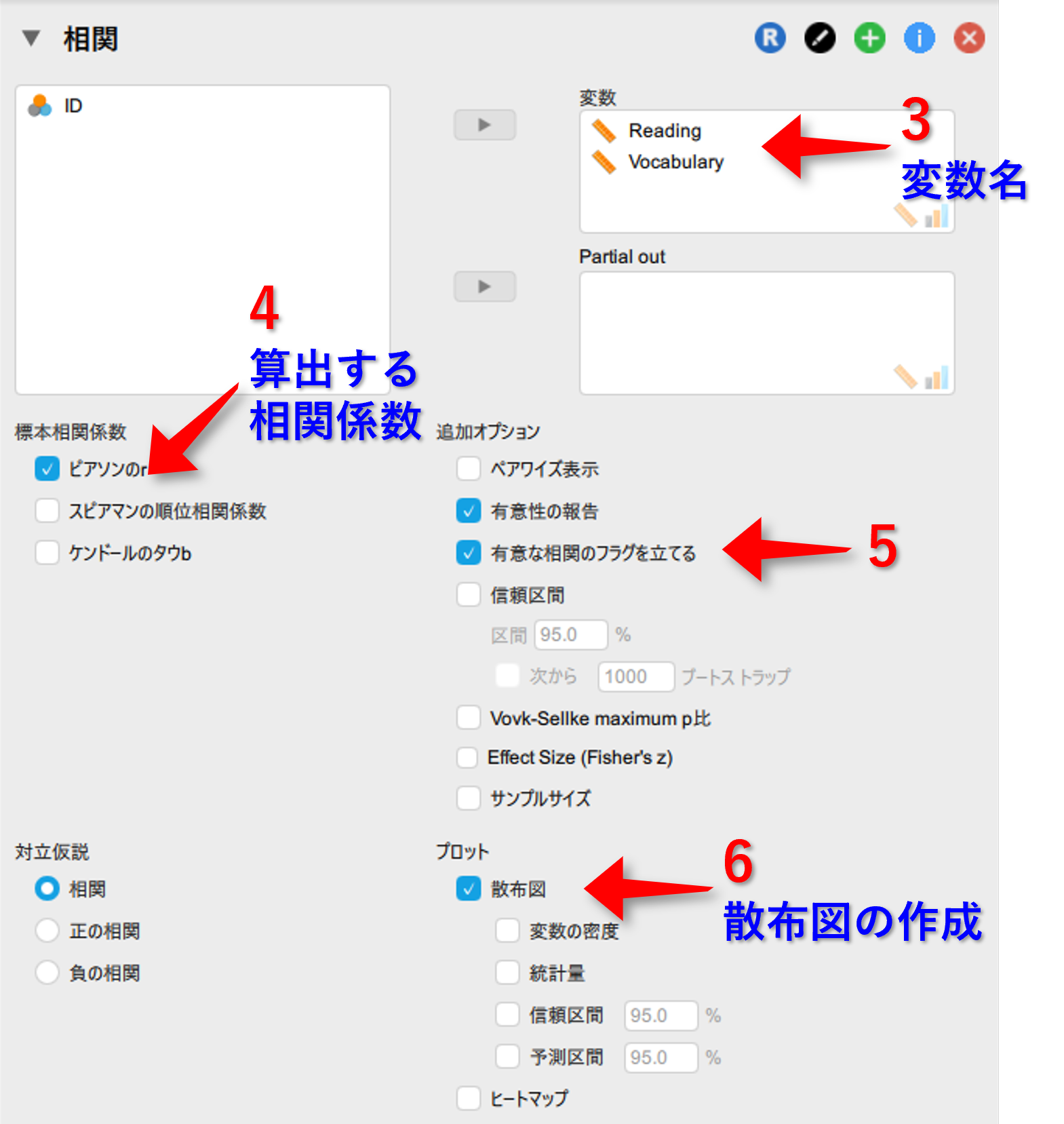
- 変数に量的変数2つを移動させる
- 標本相関係数のピアソンのrを☑にする(最初から☑になっている)
- 追加オプションの中の有意な相関のフラグを立てるを☑にする
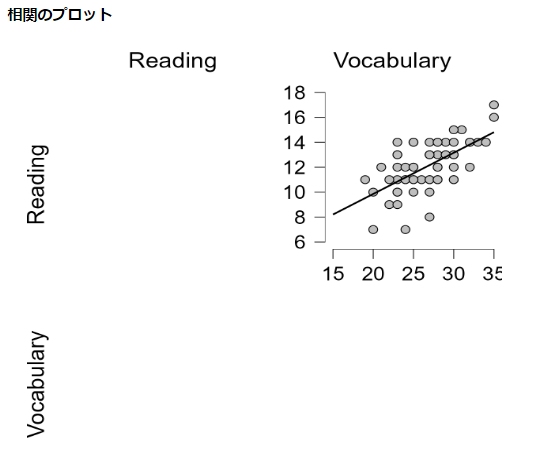
- プロットの中の散布図を☑にする